我为何要收集这些图片
起初,我发现了一个动漫星空的随机API(https://api.dongmanxingkong.com/)(现在已经挂了,做这个的服务器开销本来就很大,虽然图床是第三方的,但高并发起来开销真的很恐怖,所以谁愿意去做呢),再加上我喜欢收藏资源,于是我突发奇想想要自己收集这些图片的链接和文件
我从何处获取数据
最开始呢,我采用了一种非常笨的办法,就是直接暴力去爬取一个随机API,通常这些图片都不是按顺序输出的,所以当时我能想到的也就只有这个办法,这个简陋的脚本开源在https://github.com/xiwangly2/php_img_spider,限于我的技术能力我用PHP编写了这个脚本(Python应该是更好的选择)
部分展示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| <?php
$url = 'https://api.dongmanxingkong.com/suijitupian/acg/1080p/index.php';
$img = @file_get_contents($url);
$uuid = uniqid();
if(!file_exists("images"))
{
@mkdir("images");
}
if(!file_exists("imagestemp"))
{
@mkdir("imagetemp");
}
@file_put_contents("./imagetemp/{$uuid}imgdata.bin",$img);
$info = @getimagesize("./imagetemp/{$uuid}imgdata.bin");
$md5 = @md5_file("./imagetemp/{$uuid}imgdata.bin");
$mime = $info["mime"];
if($mime == "image/png")
{
$filetype = ".png";
}
elseif($mime == "image/jpeg")
{
$filetype = ".jpeg";
}
elseif($mime == "image/gif")
{
$filetype = ".gif";
}
elseif($mime == "image/vnd.wap.wbmp")
{
$filetype = ".wbmp";
}
elseif($mime == "image/x-xbitmap")
{
$filetype = ".xbm";
}
elseif($mime == "image/webp")
{
$filetype = ".webp";
}
elseif($mime == "image/bmp")
{
$filetype = ".bmp";
}
else
{
$filetype = ".bin";
}
$filename = "{$md5}{$filetype}";
echo("{$filename}");
if(file_exists("./images/{$filename}"))
{
echo("<br/>重复!");
@file_put_contents("./images/{$filename}",$img);
}
else
{
@file_put_contents("./images/{$filename}",$img);
}
@unlink("./imagetemp/{$uuid}imgdata.bin");
?>
|
直到有一天,我想起了GitHub的神奇搜索功能,直接用已知的信息搜索全文内容,比如:
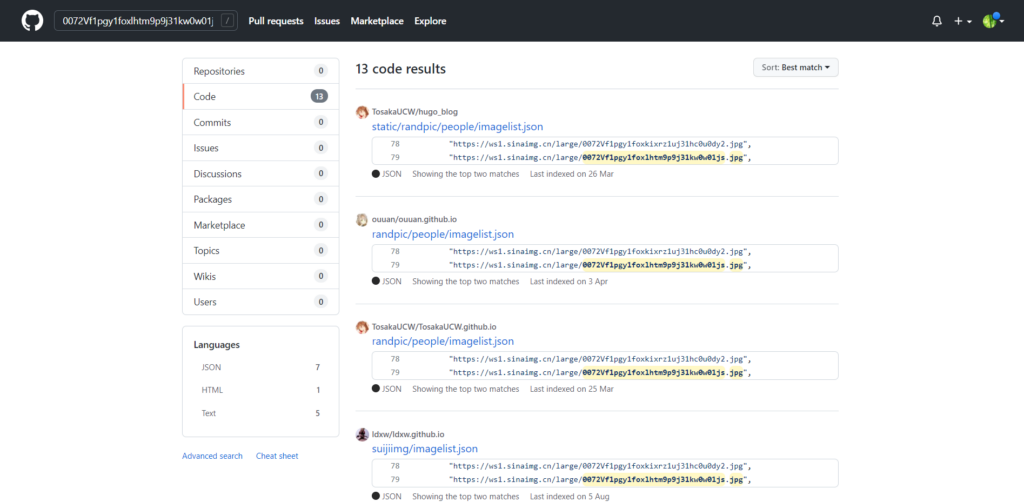
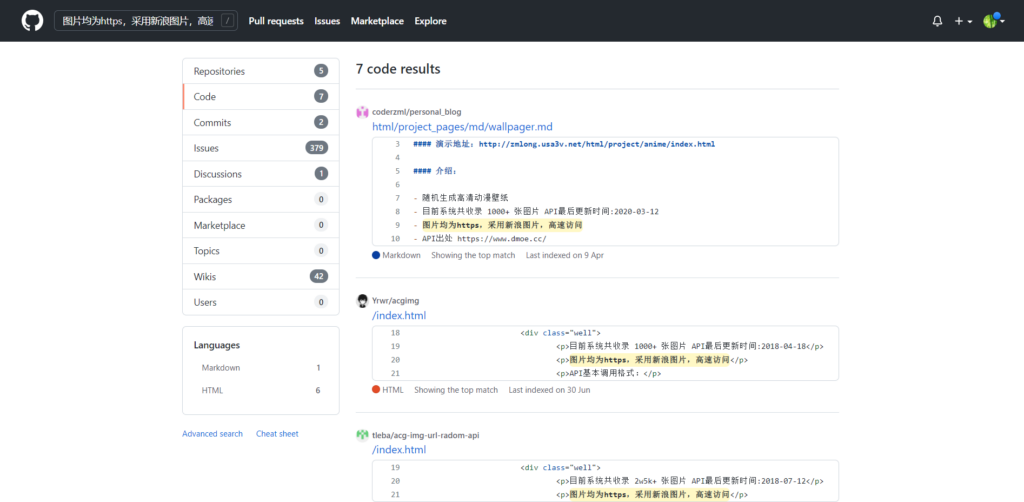
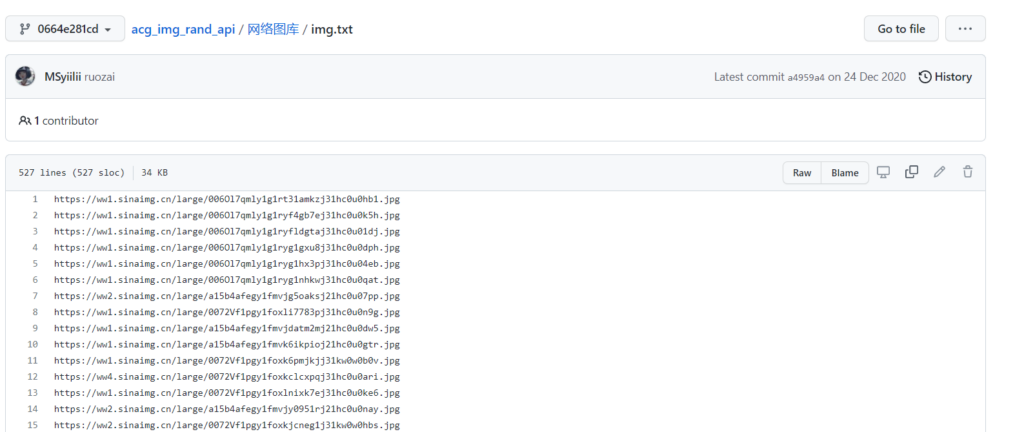
很快啊,我找到了他们的API使用的数据源

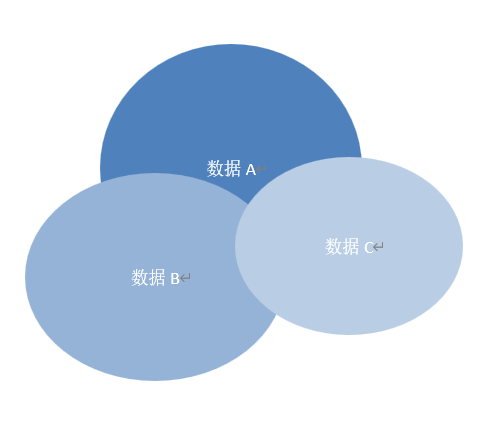
sinetxt.txt,当我再细心比对时发现,虽然很多同一个项目的文件名或项目结构大致相同,但图床链接内容不大相同
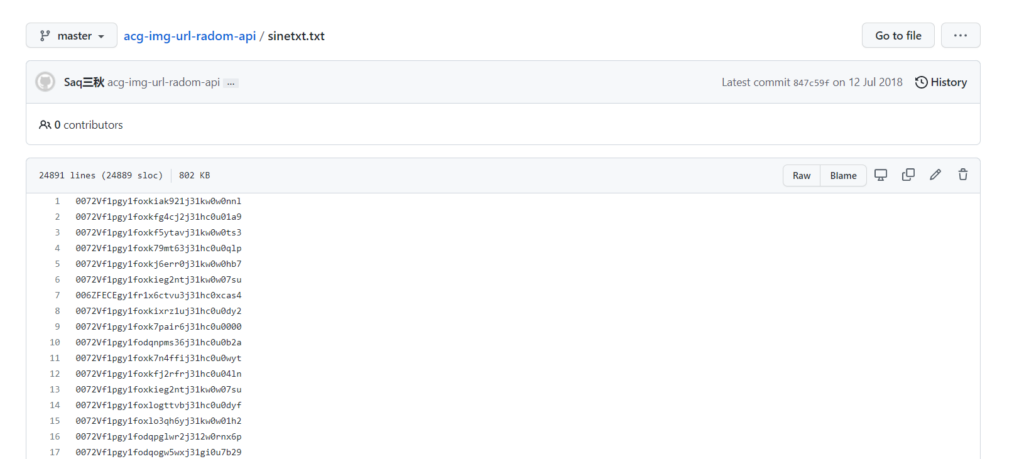
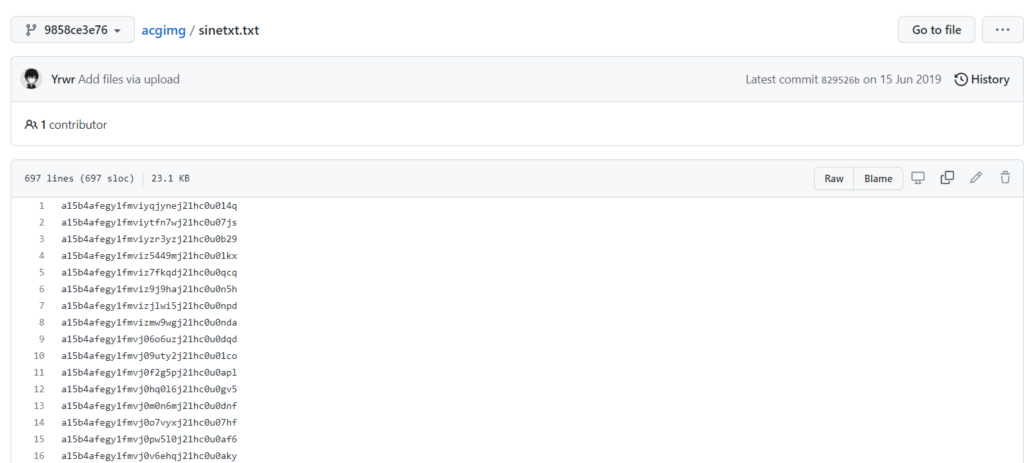
并且多数的数据文件之间都达不成真子集关系,示意图
我该如何处理数据
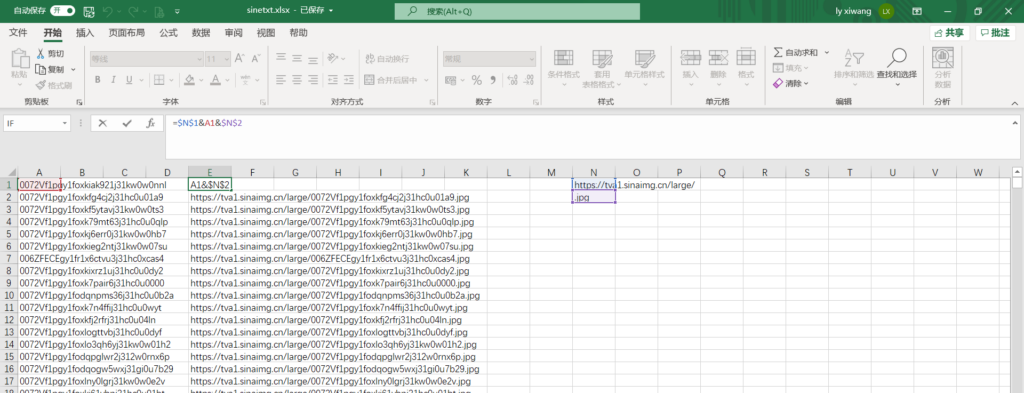
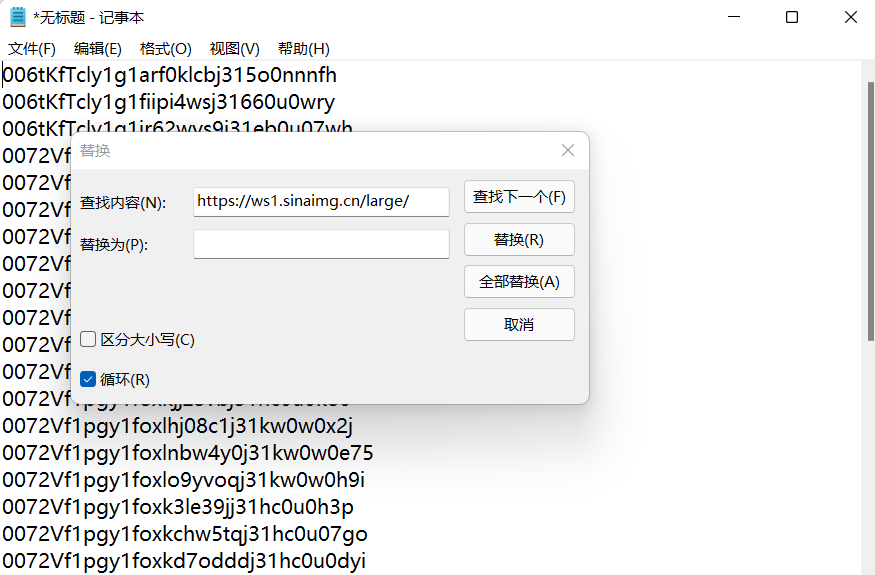
于是我就尝试聚合这些数据,利用Excel的文字操作功能、记事本和Notepad++的替换功能将这些数据转换成统一的格式:
从何处获得我收集的数据
整理好的文件我放在了https://github.com/xiwangly2/acg-img-url-radom-api,有需要的可以拿去用。sinetxt-xiwangly.txt目前我只加入了二次元图片(偶见分类错误),其他类型的图片尚未添加。
sinetxt.xlsx就是我用来处理这些数据的表格,里面还有一些除二次元外其它类型的图片。
这应该是目前全网最全的新浪二次元图片收集了吧,后续我可能会收集其他网站的图床图片,如果你是开随机图片的站长,如果你发现服务器有一段时间有个IP大量的请求随机图片就有可能是我在爬图片,如果正在看这篇文章的您有这样类似的图片资源,可以给我分享一下,帮助我完善图片资源。
之前收集的二次元图片我放在了阿里云盘上,通过我的网站转发:https://pan.xiwangly.com/%E9%98%BF%E9%87%8C%E4%BA%91%E7%9B%98/%E5%9B%BE%E7%89%87
你也可以通过调用我的API来获取这些图片,见我的另一篇文章:
https://www.xiwangly.com/api-documentation.html#ACG随机图片
然后我写了(不对,是搬了)一个随机输出图片的脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| <?php
// 存储数据的文件
$filename = 'sinetxt-xiwangly.txt';
if(!file_exists($filename)) {
die($filename.'数据文件不存在');
} else {
//读取资源文件
$giturlArr = file($filename);
}
$giturlData = [];
//将资源文件写入数组
foreach ($giturlArr as $key => $value) {
$value = trim($value);
if (!empty($value)) {
$giturlData[] = trim($value);
}
}
//随机输出一张
$randKey = rand(0, count($giturlData));
$imgurl = 'https://tva1.sinaimg.cn/large/'.$giturlData[$randKey];
//随机输出十张图片_后面数字可改
$randKeys = array_rand($giturlData, 10);
$imgurls = [];
foreach ($randKeys as $key) {
$imgurls[] = 'https://tva1.sinaimg.cn/large/'.$giturlData[$key];
}
//json格式
$returnType = $_GET['return'];
switch ($returnType) {
//浏览器直接输出图片
case 'img':
$img = file_get_contents($imgurl, true);
header("Content-Type: image/jpeg;");
echo $img;
break;
//随机JSON输出10张图片
case 'jsonpro':
header('Content-type:text/json');
//随机输出十张
case 'jsonpro':
$json['imgurls'] = $imgurls;
echo json_encode($json,JSON_PRETTY_PRINTJSON_UNESCAPED_SLASHES);
break;
//JSON格式输出
case 'json':
$json['code'] = '200';
$json['imgurl'] = $imgurl;
$imageInfo = getimagesize($imgurl);
$json['width'] = "$imageInfo[0]";
$json['height'] = "$imageInfo[1]";
$json['mime'] = "$imageInfo[mime]";
header('Content-type:text/json');
echo json_encode($json,JSON_UNESCAPED_SLASHES);
break;
//直接跳转
default:
header("Location:" . $imgurl);
break;
}
?>
|
我在原基础上加上了MIME的输出,然后设置JSON的输出不转义特殊字符。
然后就可以实现随机图片了。
真是爆肝啊,要收集尽可能多的新浪图片URL并去重整理,最后下载他们,真不是件易事!